
המהפכה של אוטומציית מנועי חיפוש ישירות משורת הפקודה
עולם השיווק הדיגיטלי עבר תהפוכות רבות מאז שהתחלתי את דרכי בשנת אלפיים וארבע עשרה. בעבר הרחוק נאלצנו לעבור ידנית על מאות עמודים של מתחרים, להעתיק כותרות, לנסות להבין איזה תוכן חסר לנו באתר ולקוות שהאסטרטגיה שלנו תעבוד. כיום, כל מומחה קידום אתרים יודע שהמידע נמצא שם בחוץ והאתגר האמיתי הוא לאסוף אותו בצורה חכמה ומאורגנת. כאן בדיוק נכנסת לתמונה הטכנולוגיה של קלוד קוד המאפשרת לנו לכתוב סקריפטים מורכבים של קצירת מידע ישירות מהטרמינל שלנו.
השימוש בטרמינל לייצור מודיעין תחרותי משנה את חוקי המשחק. במקום לפתוח דפדפנים כבדים ולעבוד עם תוספים שקורסים, אנחנו בונים סביבת צד שרת קלה ומהירה. קלוד קוד מאפשר למפתחים ולמקדמי אתרים להזין פקודות בשפה טבעית ולקבל בתמורה קוד פייתון או נוד מדויק שיוצא לסרוק את הרשת. התוצאה היא מערכת מודיעין פרטית שעובדת עשרים וארבע שעות ביממה, אוספת נתונים, משווה אותם לאתר שלנו ומציפה פערים קריטיים שמונעים מאיתנו להתברג במקומות הראשונים.
למה כדאי לנטוש את הכלים המסורתיים ולעבור לפיתוח עצמאי
מערכות המדף המוכרות עושות עבודה נהדרת אך הן מוגבלות. הן מספקות את אותם הנתונים בדיוק לכם ולמתחרים שלכם. כאשר אתם מפתחים כלי קצירת מידע עצמאי אתם קובעים את החוקים. אתם יכולים להחליט אילו פרמטרים לחלץ, באיזו תדירות לבצע את הסריקה ואיך להצליב את המידע. יתרה מכך, היכולת לשלב ניתוח שפה טבעית על התוכן הנשאב מאפשרת הבנה סמנטית עמוקה של כוונת הגולש, דבר שכלים גנריים מתקשים לספק ברמה הנדרשת לשוק המקומי.
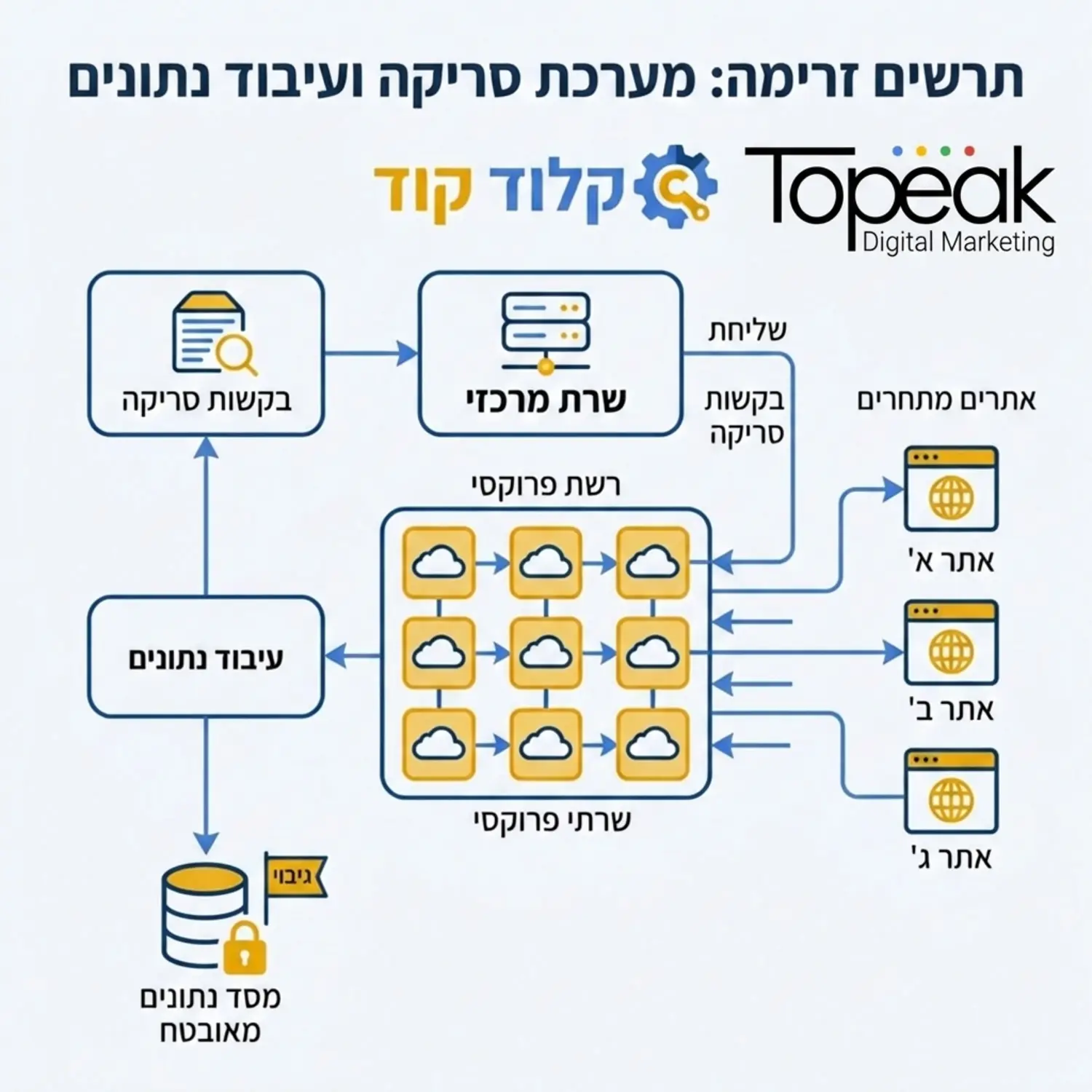
ארכיטקטורת צד שרת לאיסוף נתונים אוטומטי
כדי לבנות מערכת יעילה שתשרת את האסטרטגיה שלנו יש להבין את הארכיטקטורה הנדרשת. בבסיס המערכת עומד שרת וירטואלי שמריץ את הסקריפטים שלנו באופן מחזורי. השרת הזה מתחבר לרשת של כתובות איי פי מתחלפות כדי למנוע חסימות ומפעיל דפדפנים נטולי ממשק גרפי שמדמים התנהגות של גולש אמיתי. בצורה זו אנו מצליחים לעקוף מנגנוני הגנה מתקדמים של אתרים ולאסוף את המידע הדרוש לנו בצורה חלקה.
השילוב של קלוד קוד בתוך תהליך הבנייה מאפשר לנו להאיץ את הפיתוח פלאים. אם בעבר היינו צריכים לכתוב עשרות שורות קוד רק כדי לטפל בשגיאות התחברות או לנתח מבנה של טבלת נתונים, היום פקודה פשוטה בטרמינל מייצרת עבורנו את הפונקציות הנדרשות. קלוד יודע לנתח את קוד המקור של אתר המטרה ולהתאים את פקודות השאיבה למבנה הספציפי שלו, מה שחוסך שעות רבות של תסכול וניסוי וטעייה.
בחירת שפת הפיתוח והסביבה הווירטואלית
לרוב פייתון היא השפה המועדפת למשימות של קצירת מידע באינטרנט בזכות ספריות חזקות כמו ביוטיפול סופ וסקרייפי. עם זאת בסביבות שדורשות רינדור כבד של קוד ג’אווה סקריפט נעדיף להשתמש בכלים מבוססי נוד כמו פאפטיר. היופי בעבודה עם עוזר תכנות חכם בטרמינל הוא שאין צורך לזכור את התחביר המדויק של כל ספריה. אנו פשוט מגדירים את המטרה והמודל מייצר עבורנו את הקוד האופטימלי לסביבה שבחרנו.
שאיבת פרופילי קישורים ומחקר מתחרים עמוק
אחד האתגרים הגדולים בכל תהליך של קידום אורגני הוא להבין מאיפה המתחרים מקבלים את הכוח שלהם. בניית פרופיל קישורים דורשת משאבים רבים ואם נוכל לנתח את מקורות הכוח של המובילים בנישה נוכל לשכפל את הצלחתם או למצוא מקורות טובים יותר. המערכת שאנו בונים יכולה לסרוק אינדקסים ציבוריים או לחלץ נתונים מתוך מנועי חיפוש כדי למפות את כל הקישורים הנכנסים לעמוד ספציפי של מתחרה.
הסקריפט שואב את הכתובת המקשרת, מזהה את טקסט העוגן המדויק ומנתח את ההקשר שבו הקישור מופיע. נתונים אלו נשמרים במסד הנתונים שלנו ומאפשרים לנו לייצר מפת קשרים ענפה. כאשר אנו מריצים את הסקריפט על עשרת התוצאות הראשונות אנו מקבלים רשימה ממוקדת של פורטלים, בלוגים ואתרי חדשות שמעניקים ערך אמיתי בנישה שלנו. זוהי רשימת עבודה יקרה מפז לכל קמפיין של בניית סמכות ברשת.
זיהוי סמכות דומיין ואסטרטגיית בניית קישורים
לאחר שאספנו את המידע הגולמי עלינו לסנן אותו. קלוד קוד יכול לעזור לנו לכתוב אלגוריתם פנימי שמעריך את איכות הקישור על בסיס פרמטרים כמו כמות התנועה באתר המקשר, הרלוונטיות התוכנית והיחס בין קישורים יוצאים לנכנסים. תהליך זה של ניקוי וטיוב הנתונים מבטיח שאנו ממקדים את מאמצי ההשגה שלנו רק באתרים שיניבו תמורה אמיתית ולא באתרי ספאם שעלולים להזיק לנו בטווח הארוך.
מציאת פערים בתוכן באמצעות עיבוד שפה טבעית
אחרי שטיפלנו בצד של הסמכות החיצונית הגיע הזמן לצלול פנימה אל התוכן עצמו. גוגל ומנועי חיפוש אחרים מתגמלים עמודים שמספקים את התשובה המקיפה והטובה ביותר לשאילתת הגולש. כדי לנצח מתחרה חזק אי אפשר להסתפק בתוכן דומה, עלינו למצוא מה הוא שכח לכתוב. סקריפינג של פערי תוכן הוא תהליך שבו הבוט שלנו שואב את כל המאמרים המדורגים בראש התוצאות ומפרק אותם לגורמים.
הבוט מנתח את מבנה הכותרות, שולף את רשימת הנושאים המרכזיים שכל מתחרה מכסה ומשווה אותה למאמר שלנו. באמצעות שימוש בספריות לעיבוד שפה טבעית המערכת מזהה מילות מפתח, ביטויים סמנטיים ושאלות נפוצות שמופיעות אצל המתחרים אך נעדרות מהאתר שלנו. התוצאה היא דוח מפורט שאומר לנו בדיוק אילו פסקאות להוסיף, אילו שאלות לענות עליהן ואיך לשפר את העומק של המאמר הקיים.
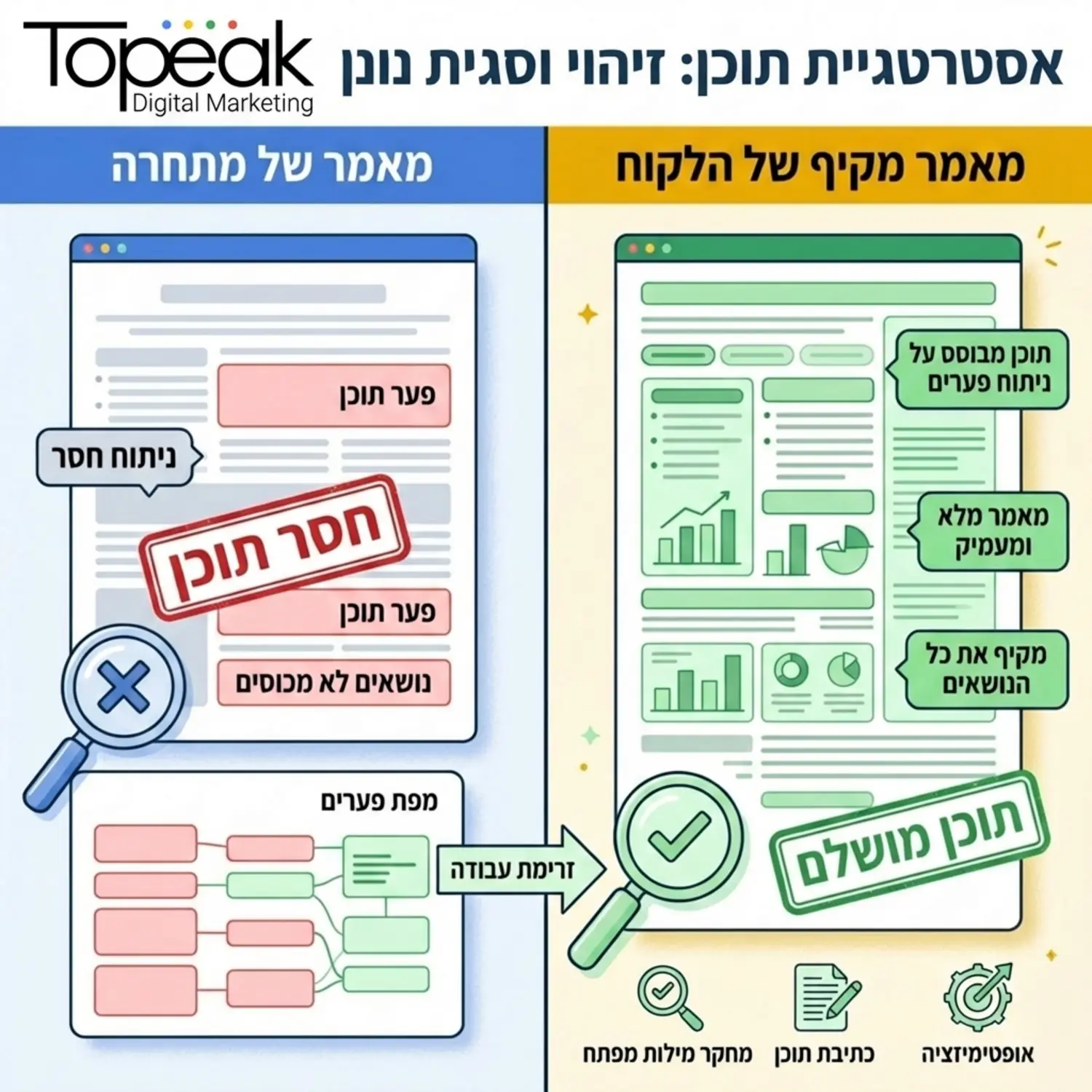
ניתוח מבנה העמוד וכותרות מתחרים
מבנה העמוד מעיד רבות על האופן שבו בעל האתר מארגן את המידע עבור הגולש ומנוע החיפוש. סקריפט ייעודי רץ על תגיות הכותרות מחלץ את ההיררכיה ומציג לנו עץ נושאים. אם כל המתחרים שלנו כתבו פסקה על היבטים חוקיים של התחום ואנחנו דילגנו על כך, המערכת תתריע על פער משמעותי. הבנה זו מאפשרת לעורכי התוכן שלנו לייצר סילבוס מושלם לכל מאמר לפני תחילת הכתיבה.
בניית המערכת צעד אחר צעד עם שורת הפקודה
כעת ניגש אל הפרקטיקה ונבין כיצד התהליך מתבצע בפועל. תחילה אנו פותחים את הטרמינל שלנו ומוודאים שסביבת העבודה הווירטואלית פעילה. אנו קוראים לקלוד קוד ומבקשים ממנו לאתחל פרויקט חדש המיועד לאיסוף נתונים מתוצאות החיפוש. המודל ייצור עבורנו את קבצי ההגדרות, יתקין את התלויות הנדרשות ויכין את קובץ הריצה הראשי. מדהים לראות כיצד משימה שבעבר דרשה שעות של קינפוגים מתבצעת כעת בתוך דקות ספורות.
השלב הבא הוא הגדרת הפונקציה המרכזית שתקבל רשימה של מילות מפתח מתוך קובץ ותשלח בקשות לדפי התוצאות. כאן אנו מבקשים מהעוזר שלנו לשלב מנגנון של השהיות אקראיות בין בקשה לבקשה, כדי לחקות קצב קריאה אנושי ולא לעורר חשד בקרב חומות האש של מנועי החיפוש. הפלט המתקבל נשמר לתוך טבלאות מסודרות המוכנות לניתוח המשך.
טבלת השוואה בין סקריפינג עצמאי למערכות קיימות
| פרמטר להשוואה | פיתוח סקריפינג עצמאי בטרמינל | שימוש במערכות מדף מסחריות |
|---|---|---|
| עלות שוטפת | נמוכה מאוד תשלום רק על שרת ופרוקסי | גבוהה מנוי חודשי יקר למשתמשים |
| גמישות והתאמה | מוחלטת ניתן לאסוף כל נתון רצוי | מוגבלת למה שהפלטפורמה בחרה להציג |
| זמן אמת | איסוף נתונים עכשווי ומיידי | עיכוב של ימים או שבועות בעדכון הנתונים |
| ייחודיות המידע | בלעדי לארגון שלך בלבד | זמין לכל המתחרים שמשלמים על השירות |
כפי שניתן לראות בטבלה, כאשר אנו מפתחים כלי לקידום אתרים במתכונת אישית, אנו מרוויחים שליטה מלאה על מאגר הנתונים שלנו. אמנם נדרשת השקעה ראשונית בהקמת התשתית אך השילוב של בינה מלאכותית מוריד את רף הכניסה ומאפשר גם למי שאינו מתכנת מלידה לייצר כלים עסקיים ברמה הגבוהה ביותר.
היבטים חוקיים ואתיים באיסוף מידע ברשת
אי אפשר לדבר על סקריפינג מבלי להתייחס לצד החוקי והאתי של הפעולה. רשת האינטרנט אמנם פתוחה אך לכל אתר ישנם כללים לגבי הדרך שבה מותר לגשת למידע שלו. לפני כל פרויקט של איסוף נתונים אנו מחויבים לבדוק את קובץ הרובוטס של האתר המותקף ולוודא שאיננו עוברים על הנחיות מפורשות של בעלי האתר. איסוף מידע פומבי מותר בדרך כלל אך חשוב לעשות זאת במידתיות ותוך כיבוד משאבי השרת של הצד השני.
חשוב מאוד לעיין במידע רשמי כמו הנחיות גוגל לסורקים כדי להבין את הסטנדרט בתעשייה. בוט טוב מזדהה כראוי, מכבד הגבלות קצב קריאה ולא מעמיס על שרתי המטרה עד כדי קריסתם. כאשר אנו מבקשים מקלוד קוד לכתוב את הסקריפט, אנו מנחים אותו להוסיף מגבלות קצב והשהיות חכמות שמבטיחות פעילות שקטה, אתית וחוקית שלא תסבך אותנו או את הלקוחות שלנו.

ייעול התהליך ושמירת הנתונים במסד נתונים
לאחר שהנתונים נאספו בצורה בטוחה הם מועברים לשלב העיבוד. נתונים גולמיים הם חסרי ערך אם לא ניתן להפיק מהם תובנות. אנו משתמשים במסדי נתונים רלוציוניים או מבוססי מסמכים כדי לשמור את ההיסטוריה של הסריקות. שמירת ההיסטוריה קריטית מפני שהיא מאפשרת לנו לזהות מגמות לאורך זמן. למשל נוכל לראות מתי מתחרה מסוים התחיל לאבד מיקומים ואילו שינויים בתוכן או בקישורים הובילו לכך.
בסופו של יום המערכת מפיקה דשבורד ברור ומאיר עיניים המציג את הפערים בדיוק רב. מנהל הקמפיין יכול להיכנס בבוקר למערכת, לראות אילו עמודים דורשים חיזוק של קישורים, היכן חסר תוכן משמעותי ואילו מתחרים חדשים צצו בזירה. ארכיטקטורת צד שרת יחד עם עוזר בינה מלאכותית בטרמינל הופכים את המחקר המייגע למכונה משומנת שמייצרת תוצאות בשטח ומשאירה את המתחרים הרחק מאחור.







